The data compatibility blog,
Join the discussion
Universal Dataset Interoperability is a Giant Leap Forward for IT
0 June 5, 2025

The Silver Bullet
Current datasets do not interact freely and therefore remain data silos. Siloed datasets have hindered business and IT for over three decades. Conversely, our universally interoperable datasets enable seamless interaction across enterprises, industries, or globally. Our Universal Dataset Interoperability provides the data solution that IT departments, businesses, and industries have long sought. In theory, you can enrich all datasets to ensure universal interoperability.
What is Universal Dataset Interoperability?
Universal Dataset Interoperability ensures that all datasets are implemented to work together seamlessly, facilitating data unity, sharing, and collaboration across various platforms and systems.
These universally interoperable datasets are:
- Easy to implement by noninvasive enrichment of existing datasets.
- Dynamically connectable plug-and-play modules that comply with FAIR data principles.
- Independently managed with retained ownership and dataset security.
- Functioning collectively as a Modular Data Fabric with unlimited scalability and end-to-end data integrity.
Our independent research indicates that the secret to Universal Dataset Interoperability lies in the data context of each dataset. The data context of a dataset refers to the shell of master data that encapsulates each dataset. Siloed datasets, due to their inconsistent data contexts, lack the data integrity necessary for interoperability. Conversely, Universally Interoperable Datasets(UIDs) reside within a universal dataset context that ensures data integrity, thereby facilitating interactions between UIDs. All UIDs interact repeatedly and reliably through their universal data contexts. These UIDs are meticulously crafted to be analytics-ready, modular, plug-and-play datasets. Our UIDs are a clear game-changer for business and IT.
Data Architectures for Universally Interoperable Datasets
Typical data architectures are based on siloed datasets. These disparate data architectures are fragmented, disjointed and filled with redundant data of poor quality that lack data integrity. Conversely, our universally interoperable datasets offer unlimited potential for Modular Data Fabric data architectures, wherein all UIDs collaborate seamlessly to meet any data requirements.
In Figure 1, we illustrate a Modular Data Fabric Architecture example designed specifically to support modern technologies, such as AI/ML and Knowledge Graph. We create all the datasets in our Modular Data Fabric to be universally interoperable and analytics-ready. Additionally, we incorporate domain-specific master data golden record UIDs into the fabric, as depicted in Figure 1. With the implementation of Golden Record UIDs, we substantially enhance the quality of data shared across the fabric. We can combine selected UIDs of the fabric, either dynamically or physically materialized, to fulfill specific use case needs. We illustrate materialized UIDs in the UID Use Case Library of Figure 1.
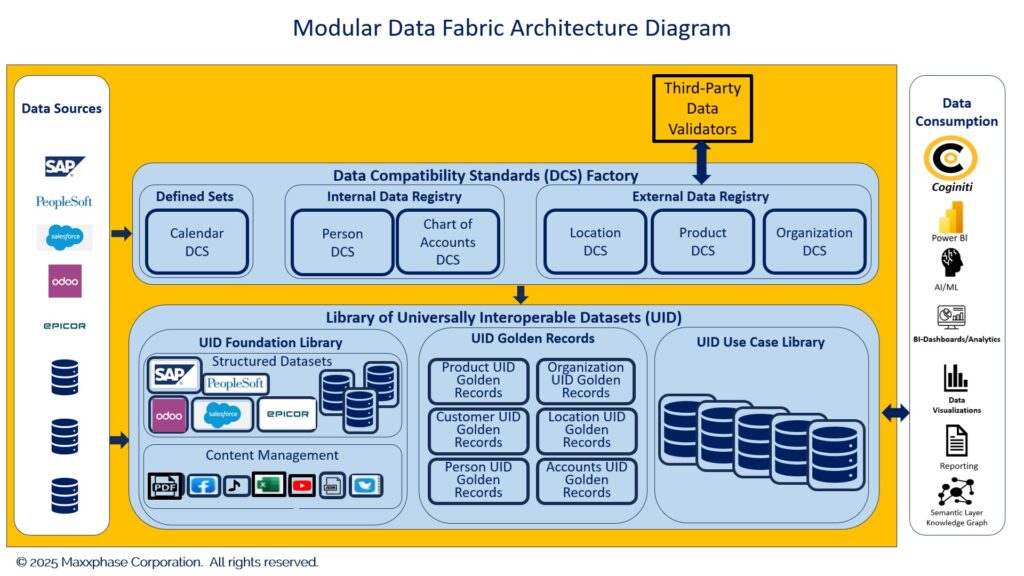
Modular Data Fabric containing a Data Compatibility Standards Factory and the Library of Universally Interoperable Datasets.
Modular Data Fabrics are also universally interoperable, allowing datasets to be combined across fabrics, provided the proper hardware connections and security permissions have been established.
Universal Dataset Interoperability Use Cases
Universally interoperable datasets establish a contemporary data foundation that revolutionizes both IT and business. Easy and low cost of development, flexibility, reliability, scalability, and time to market all favor universal interoperability over conventional data integration methods. Use cases that are not possible or even practical for data integration methods are easily achieved with universal interoperability. The universal interoperability of datasets now enables use cases for intricate industries, such as supply chain management and healthcare, by ensuring seamless interoperability and functionality across diverse datasets and data fabrics.
Maxxphase is the sole provider of our patented methods: Compatible Data Modeling, Object-Oriented Data Management, Data Compatibility Standards, Universally Interoperable Datasets and Modular Data Fabrics. For inquiries, comments, or to discuss use cases, please don’t hesitate to contact us.