The data compatibility blog,
Join the discussion
Compatible Data Modeling
0 January 10, 2025

Compatible Data Modeling is an innovative modernization of traditional data modeling methods. Fundamentally, Compatible Data Modeling addresses the lack of referential data integrity between datasets instantiated from traditional data models. You can only design disparate, siloed datasets with traditional data modeling, while Compatible Data Modeling produces directly interoperable datasets. Directly interoperable datasets are plug-and-play component datasets that you can seamlessly join, on-demand, to function collectively like a single consistent dataset.
Traditional Data Modeling
Traditional data modeling methods have always focused on designing individual datasets in their physical data models, ignoring that most datasets eventually need to work together. As a result, instantiated datasets are isolated silos without referential data integrity enforced between datasets. Siloed datasets have been a problem for IT and businesses for over three decades.
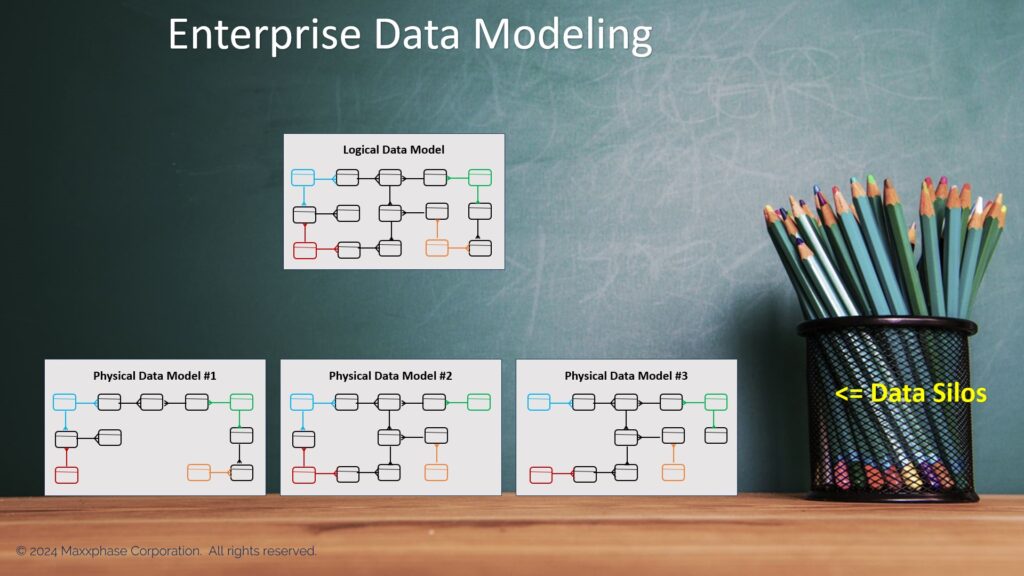
Figure 1: Siloed Physical Data Models
In Figure 1, we use an Enterprise Logical Data Model to produce three physical data models using traditional data modeling methods. Since no relationships exist between the three physical data models, each is isolated. We form siloed datasets when we instantiate them from isolated physical data models.
Compatible Data Modeling
Our patented Compatible Data Modeling builds upon traditional data modeling approaches to support the creation of directly interoperable datasets. Directly interoperable datasets spontaneously form a data fabric with end-to-end referential data integrity enforcement. Directly interoperable datasets eliminate the need for downstream data processing as direct dataset interoperability replaces ETL-based data integration. You can enrich any data model to be a Compatible Data Model and any datasets to be part of a directly interoperable data fabric.
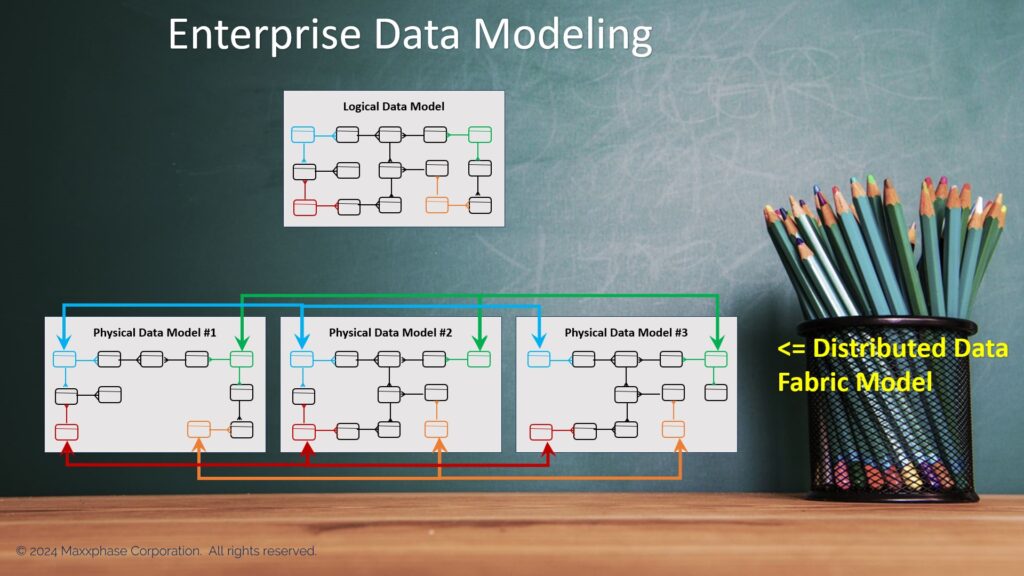
Figure 2: Data Fabric Physical Data Model
In Figure 2, an Enterprise Logical Data Model forms three physical data models using traditional data modeling methods. Peer entity relationships are then added to each of the three physical data models using Compatible Data Modeling methods. The resultant physical data model represents a Distributed Data Fabric. The peer relationships indicate that external referential data integrity must be enforced between the three datasets when instantiating them.
Data Compatibility Standard (DCS) Data Entities
A key feature of Compatible Data Modeling is the introduction of DCS data entities. We designed DCS data entities to form a universal dataset gateway encapsulating every compatible data model. This encapsulation forms plug-and-play interoperable, modular data models. Therefore, any traditional data model can be enhanced and enriched to become a Modular Plug-and-Play Data Model. Likewise, any existing disparate dataset can be enhanced non-invasively to become an Analytics-Ready Modular Plug-and-Play Dataset. The DCS universal dataset gateway ensures direct dataset interoperability when we instantiate datasets from modular Compatible Data Models.
Peer Entity Relationships
Compatible Data Modeling defines a new type of data entity relationship called a Peer Entity Relationship. Our patented Peer Entity Relationship aims to relate multiple peer DCS Data Entities and to indicate the enforcement of referential data integrity between the peer DCS Data Entities. Our Peer Entity Relationships relate peer DCS data entities across multiple compatible data models. Peer Entity Relationships provide plug-and-play functionality to compatible data models that allow two or more Compatible Data Models to be connected. When we instantiate compatible datasets from compatible data models, the DCS universal dataset gateway of each compatible dataset becomes plug-and-play. This plug-and-play functionality between universal dataset gateways facilitates direct dataset interoperability among compatible datasets. Direct dataset interoperability allows multiple instantiated datasets to collectively act in a manner indistinguishable from a single consistent dataset.
Advanced Data Fabrics
One outcome of Compatible Data Modeling is the instantiation of a modular plug-and-play data fabric. This decentralized approach to data fabrics is only available because of the Direct Dataset Interoperability of Compatible Data Models. Modular datasets for specific master data domains, such as Customer 360 and Product 360 modular ‘Golden Record’ datasets, may be added to enhance any modular data fabric.
Direct dataset interoperability of compatible datasets replaces data integration of disparate datasets. Therefore, there is no longer a need for costly ETL-based data pipelines and dataset consolidations. Using Compatible Data Modeling methods, you can model and instantiate your entire data architecture as a data fabric with end-to-end referential data integrity and comprehensive dataset interoperability.
Siloed datasets and layered data architectures have hindered businesses for over three decades. Currently, only Compatible Data Modeling can eliminate siloed datasets while delivering advanced data fabric architectures. This robust new methodology is a game changer for how organizations draw value from their data while significantly reducing the cost and complexity.