The Modular Data Fabric Architecture
Modular Data Fabrics are built upon a set of Data Compatibility Standards. When modular data fabrics use the same set of data compatibility standards, they are universally interoperable. Universally Interoperable Modular Data Fabrics can now join datasets and unify data content across data fabrics, provided the proper security has been granted for each Universally Interoperable Dataset.
The Modular Data Fabric Architecture is a distributed platform that enables universal interoperability with multiple organizations. In fact, components of the Modular Data Fabric Architecture can be distributed across organizations and shared by multiple organizations. Each Modular Data Fabric enforces end-to-end plug-and-play data integrity to improve data quality and to support Universal Interoperability across other Modular Data Fabrics. In practice, each organization's data architecture is a distributed Modular Data Fabric.
Amazingly, Modular Data Fabric Architectures are compatible with and noninvasive to existing data architectures. Just as the Data Compatibility Standards enrich existing datasets without modifying structural metadata, data content, or interfering with their related software, enriching your data architecture is also noninvasive. All existing data architecture components continue to function unencumbered by the dataset commonality, which adds dynamic dataset interoperability to each of your data architecture components.
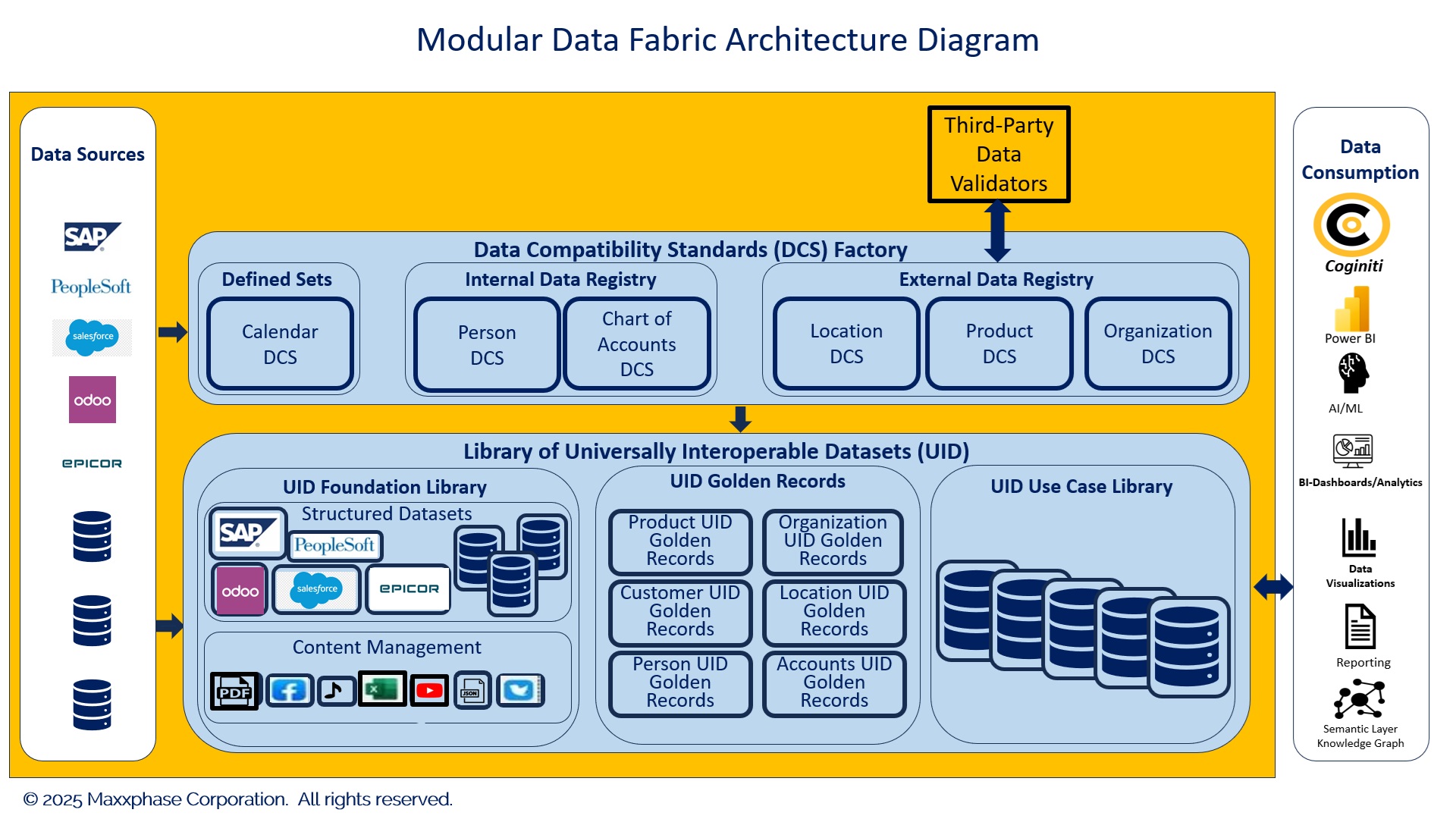
Figure 1: Maxxphase's Modular Data Fabric Architecture Example
The Data Compatibility Standards Factory
As depicted in Figure 1, Data Compatibility Standards (DCS) are created and maintained in the Data Compatibility Standards Factory. Each DCS is specifically designed for a master data domain. Each DCS can be distributed and exist in a different factory. Each DCS is then shared with multiple organizations and their respective Modular Data Fabric instances.
Within the distributed DCS factory, each standard maintains a registry of unique data records to ensure data integrity across Universally Interoperable Datasets. In some cases, third-party data validators are utilized to match data records with its data registry. Each master data domain instance from each source dataset is uniquely identified and standardized in the factory for use in the Modular Data Fabric. The primary purpose of this section of the data architecture is to ensure data integrity across Universally Interoperable Datasets in the Modular Data Fabric shown in Figure 1.
The Library of Universally Interoperable Datasets
The Library of Universally Interoperable Datasets(UIDs), shown in Figure 1, contains all Universally Interoperable Datasets. All these UIDs are directly interoperable and characterized as analytics-ready, modular, and plug-and-play. As soon as a dataset is enriched to be compatible, it becomes an integral component of the data fabric. The libraries of multiple organizations are also Universally Interoperable.
The Library of Universally Interoperable Datasets is formed spontaneously from a set of Universally Interoperable Datasets. Within the datasets, each Data Compatibility Standard contains multiple anchor points, each of which is a potential join with every other Universally Interoperable Dataset. The Modular Data Fabric comprises multiple threads that enhance data access flexibility.
The UID Foundational Library
This subdivision of the Modular Data Fabric, shown in Figure 1, contains the most granular structured, semi-structured, and unstructured datasets. These datasets are the foundation of the data fabric. Typically, source datasets that are associated with an operational data system are replicated into this subdivision. Other original, non-operational datasets can also be stored in the compatible dataset foundation. All datasets in the foundation are enriched with Data Compatibility Standards from the Data Compatibility Standards Factory.
This UID Foundational Library is the core of your Single Source of Truth. These foundational UIDs can be combined and audited to ensure correctness while redundancies are removed or nullified to cleanse the Foundational Library.
The UID Golden Records
As depicted in Figure 1, this subdivision of the Data Fabric contains compatible master datasets that store the business's golden records. This subdivision of the fabric serves as the Single Source of Truth for each data instance in the master data domain. Combining the master data Single Source of Truth with the core Single Source provides a complete foundational layer to be audited for accuracy. Redundant or erroneous data can be removed or negated from the fabric.
The purpose of the UID Golden Records is to provide a single location for data that eliminates redundancy and significantly improves data quality within the fabric. Of course, the UID golden data records can be shared with any other Universally Interoperable Datasets as needed.
The UID Use Case Library
Data Compatibility supports information building within the UID Use Case Library, as depicted in Figure 1. Any subset of data derived from the UID Foundational Library can be materialized into a UID Use Case for a more focused business use, such as KPI dashboards, periodic reporting, a compatible data warehouse, and, of course, AI/ML. Since each UID supports data warehouse functionality, derived, aggregated, and historical data may enrich each UID. In addition, universal interoperability can be used to blend multiple UIDs into a new, consolidated dataset for repeated, detailed data analysis. This form of information building is significantly more efficient than traditional data transformation and incompatible dataset consolidation methods.